剖析 Android ART Runtime (3) – Compiler
之前已经介绍了 Android ART Runtime 的背景,以及 ART 中一个比较重要的模块 dex2oat。本篇文章将带你继续深入 Android ART compiler。
一、LLVM
LLVM 是编写编译器的框架系统,以C++编写而成。这个项目有很多子项目,比如说比较出名的 clang,作为 gcc 的替代者,表现非常出色。在开发自己的编译器的时候,使用 LLVM 框架可以重用一些项目原有的代码。LLVM 把编译器的不同部分抽象成不同模块,为开发和测试带来了方便。LLVM IR (Intermediate Representation) 是 LLVM 特有的中间语言。我们还是先看看 LLVM 的一些特性。
因为 LLVM 使用模块化设计,他的框架很简单 (图片来自 aosabook):

- Frontend 把不同语言转换成通用的 LLVM IR
- LLVM 的优化模快可以对 LLVM IR 进行不用功能的优化,然后把优化后的 IR 给 Backend 处理
- Backend 的作用就是把 IR 编译成不同平台的机器码
编译器对代码的优化会对代码性能造成很大的影响,因为模块化设计。编译器设计者可以决定如何优化代码。比如说在编译时的优化,运行时的优化,以及安装时对于不同 CPU 框架的优化。 (图片来自 aosabook):

Google 使用 LLVM 框架写了一个全新的编译器,针对 dex 文件写了 frontend,对于 ARM/MIPS/X86 写了不同的 backend 进行优化。不过还有一些优化模块复用了 LLVM 项目中原有的代码。不过,ART 还处在测试版,从公开的代码来看,Google 还有很多优化工作还在进行当中。ART 对于性能的提升,不仅仅是现在我们看到的,潜力会更大。
二、ART Compiler
ART 代码的编译过程主要如下:
- 从 dex 文件中提取类和方法: /art/compiler/dex/frontend.cc
- 把方法变为为 middle level LLVM IR: /art/compiler/dex/frontend.cc
- 优化 IR: /art/compiler/dex/mir_optimization.cc
- 根绝不同的 CPU 框架,吧 middle level IR 优化为 low level IR: /art/compiler/dex/mir_optimization.cc
- 生成机器代码: /art/compiler/llvm/compiler_llvm.cc
- 写入 oat 文件: /art/compiler/elf_writer.cc
过程中涉及的比较重要的类:
- CompilerDriver: 统一管理编译器的驱动
- ParallelCompilationManager: 多线程编译
- CompileMethod: 编译 dex 方法,调用 MIRGraph 类生成 IR
- MIRGraph: 包含生成中间代码,调用优化等方法
- ArmCodeGenerator: Proxy 类,用于真正调用 ArmMir2Lir 类
- ArmMir2Lir:继承于 Mir2Lir,里面有几个关于 ARM IR 优化的 passes
- CompiledMethod:编译器将编译好的代码存入这个类并返回
ART 编译器基本流程比较简单,但是因为是编译器,其中包含的东西很多,我简单画了一个 sequence diagram。如果感兴趣的话可以深入看代码。图如下:
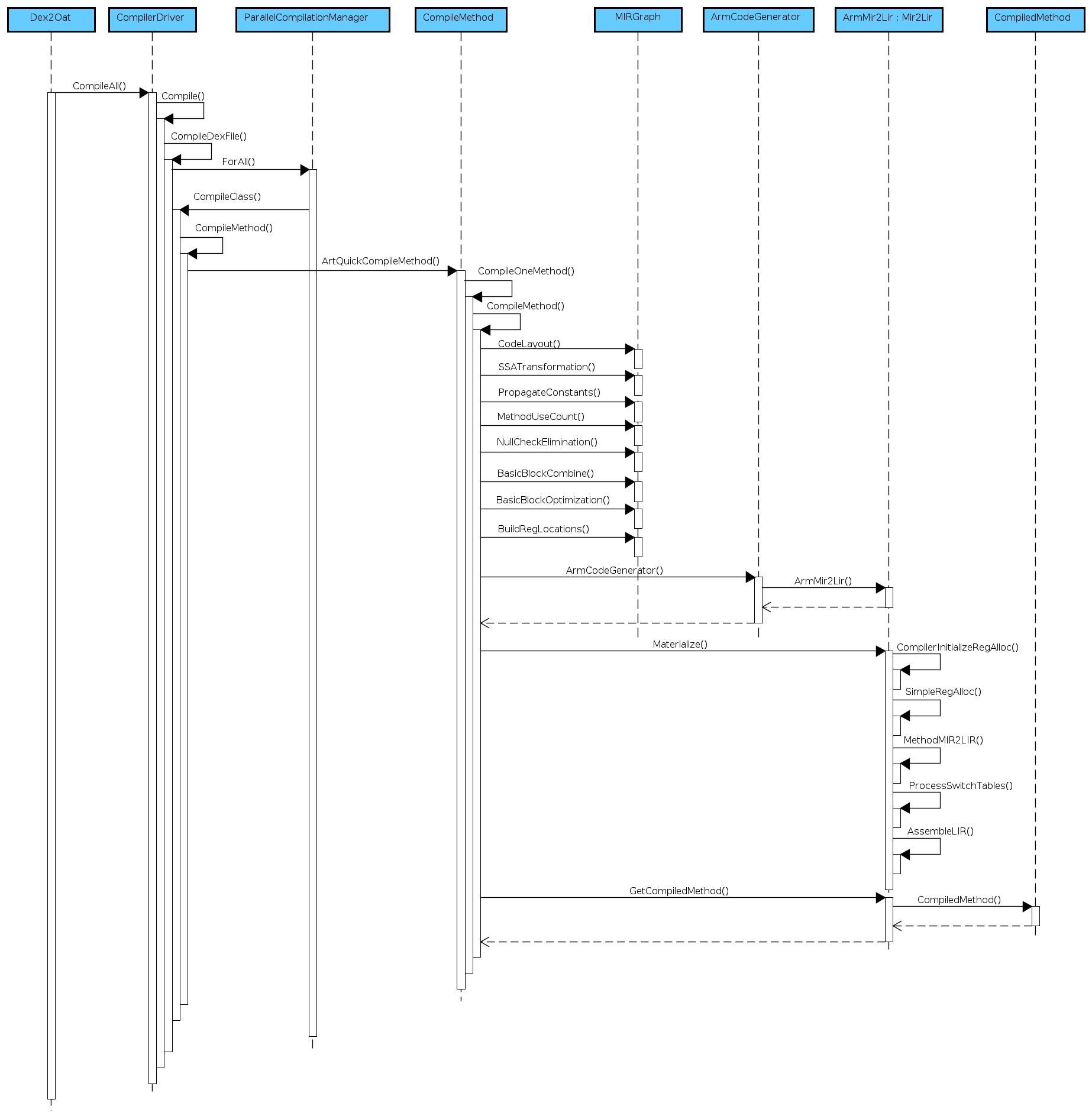
如果你觉的这个图无法直视@_@,不要紧,这里还有清晰大图。
三、关于 ART Compiler 的一些琐碎的问题
dex2oat 的参数:–compiler-backend=(Quick|QuickGBC|Portable) 有什么区别? 从代码 /art/compiler/dex/frontend.cc 中可以看到:
#if defined(ART_USE_PORTABLE_COMPILER)
if (compiler_backend == kPortable) {
cu.cg.reset(PortableCodeGenerator(&cu, cu.mir_graph.get(), &cu.arena, llvm_compilation_unit));
} else {
#endif
switch (compiler.GetInstructionSet()) {
case kThumb2:
cu.cg.reset(ArmCodeGenerator(&cu, cu.mir_graph.get(), &cu.arena));
break;
case kMips:
cu.cg.reset(MipsCodeGenerator(&cu, cu.mir_graph.get(), &cu.arena));
break;
case kX86:
cu.cg.reset(X86CodeGenerator(&cu, cu.mir_graph.get(), &cu.arena));
break;
default:
LOG(FATAL) << "Unexpected instruction set: " << compiler.GetInstructionSet();
}
#if defined(ART_USE_PORTABLE_COMPILER)
}
#endif
Portable 使用了另外一种 backend。 那 PortableCodeGenerator 又做了哪些事情呢?
Backend* PortableCodeGenerator(CompilationUnit* const cu, MIRGraph* const mir_graph,
ArenaAllocator* const arena,
llvm::LlvmCompilationUnit* const llvm_compilation_unit) {
return new MirConverter(cu, mir_graph, arena, llvm_compilation_unit);
}
我们看到了 PortableCodeGenerator 其实是用了 llvm_compilation_unit (LLVM 的 backend)。而 ArmCodeGenerator 则使用了 Google 自己写的 backend,对于 ARM 等不同 CPU 指令有不同的优化。
综上所述,形象的讲 Quick 就是编译出来的代码更加快,Portable 就是可以 port 到 LLVM 的框架上。不过 Quick mode 到底有多大的提高呢?至于另外一个 QuickGBC,代码里面还没有,估计会是 LLVM 和 Google 代码的一个结合版本。
最后,看一下目录树:
|-- portable | |-- mir_to_gbc.cc | `-- mir_to_gbc.h |-- quick | |-- arm | |-- codegen_util.cc | |-- gen_common.cc | |-- gen_invoke.cc | |-- gen_loadstore.cc | |-- local_optimizations.cc | |-- mips | |-- mir_to_lir.cc | |-- mir_to_lir.h | |-- mir_to_lir-inl.h | |-- ralloc_util.cc | `-- x86
MIR 和 LIR 是什么? 名词解释:
-
- IR: intermediate representation
- MIR: Middle IR
- LIR: Low IR
- GBC: G (generate?General?) bitcode
- bitcode: LLVM IR
在编译模型中有一种叫 Mixed model,他的大概流程是:
source code -> Lexical Analyzer -> Parser -> Semantic Analyzer -> IR Generator -> Optimizer -> Code Generator -> Postpass Optimizer -> asm code。把 MIR 和 LIR 放在模型里的位置:
IR Generator --- Medium-level IR ---> Optimizer --- Medium-level IR ---> Coder Generator -- Low-level IR ---> Postpass Optimizer。可以参考这个 slide: Multi-Level Intermediate Representations.
Reference:
Update (2016-04-07)
这篇文章写完已经过了大约两年,Android 已经出到了 Android N Preview。前几天, RednaxelaFX 发邮件解释了一些当时的疑问,很有意思,现在贴在这里供读者参考:
RednaxelaFX:
这篇对ART的编译器的分析有一些错误的地方,正好看到了所以想交流下~ 您当时看的 ART代码可能是kitkat-release版?其实那个时候LLVM相关的后端根本还没完成, QuickGBC和Portable都是基于LLVM的后端。前者的GBC是Greenland Bitcode的意思。 Greenland是ART里另外一个曾经存在过的基于LLVM的编译器,它…诶反正已经挂了不提也 罢 >_<
Dex -> MIR -> LIR -> Machine code这个路径是纯粹的Quick,其实没有任何LLVM介入的 成分~
我 :
是的,那时候比较早了,理解还不是很深刻。最近又看了 6.0 以后的 ART,发现改动 好大,Android N Preview 又加了 JIT,现在 ART 是越来越复杂了。
最后,可能之后有空再来讲讲最新的 ART Runtime 吧。BTW, 如果您也对 ART 感兴趣,可 以给我发邮件一起交流一下。