CCS 2016 Diary - Day 4
本文发表在网络安全研究国际学术论坛 (InForSec)。
会议的最后一天,我主要介绍五篇有趣的论文,包括密码研究、协议漏洞、人脸识别算法攻击、Android 内存管理子系统漏洞,和模糊测试系统。
Session 9C: Passwords
An Empirical Study of Mnemonic Sentence-based Password Generation Strategies
Weining Yang, Ninghui Li, Omar Chowdhury, Aiping Xiong and Robert W. Proctor (Purdue University)
这篇文章主要研究一种mnemonic sentence-based password generation strategies,简单来说就是找一句话,然后首字母拼起来,再做简单的变换作为密码。比如说 “to be or not to be, that is the question",转换为密码就是 "2bon2btitq"。网上很多关于如何起一个不容易被破解的密码的文章,经常会推荐这种 mnemonic sentence-based password。因为这类密码看起来是乱码,但是又很好记忆,所以经常推荐给大家。但是,这篇文章就想研究一下,这类的密码在现实当中,究竟是否安全?
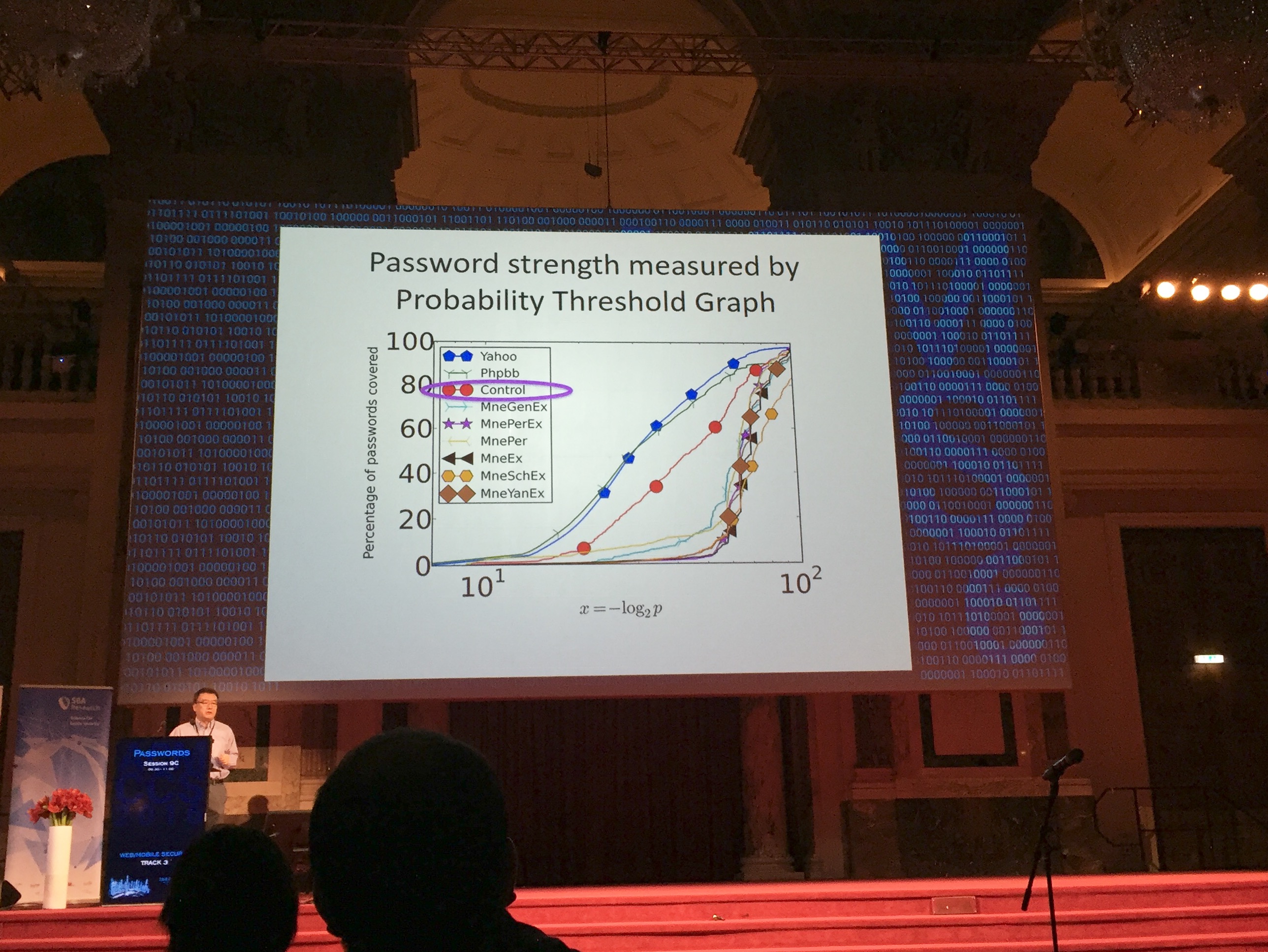
文章通过使用 Amazon Mechanical Turk 雇一些参与实验的人 ,一共进行两个实验,一个是安全性实验。包括六组不同的测试(每组实验大概 800 人参加)。实验的内容是给出一些起密码的指导意见,和例子,让参与实验的人写出自己起的密码。比如说:
- Think of a memorable sentence or phrase containing at least seven or eight words. For example, “Four score and seven years ago our fathers brought forth on this continent”.
- Select a letter, number, or a special character to represent each word. A common method is to use the first letter of every word.For example: four ⇒ 4, score ⇒ s, and ⇒ &. Combine them into a password: 4s&7yaofb4otc.
根据这组安全性数据,文章给出了一些 probability models 和 password strength meters 分析密码的安全性,得出了一些有意思的发现:
- 如果是通用的密码指导意见和例子,密码安全性会降低
- 如果要求用户使用个人的句子,并包含合适的例子,会提高密码安全性
- 例子如果是常见的句子会让密码安全性降低
- 个性化句子和高质量的例子对于设计一个安全的密码很重要
根据以上的研究,作者提出破解这种 mnemonic password 的方法。
文章还研究了密码的 usability,就是一段时间再来问用户是否能记得住之前起的密码。结论是尽管 mnemonic 密码需要花费时间去想,但是相对于控制组,recall 的比例也没有明显提高。
Session 11C More attacks
Host of Troubles: Multiple Host Ambiguities in HTTP Implementations
Jianjun Chen (Tsinghua University), Jian Jiang (University of California, Berkeley), Haixin Duan (Tsinghua University), Nicholas Weaver (International Computer Science Institute), Tao Wan (Huawei Canada) and Vern Paxson (International Computer Science Institute)

这篇文章介绍了 HTTP 协议中 Host 字段的实现不同造成的漏洞。
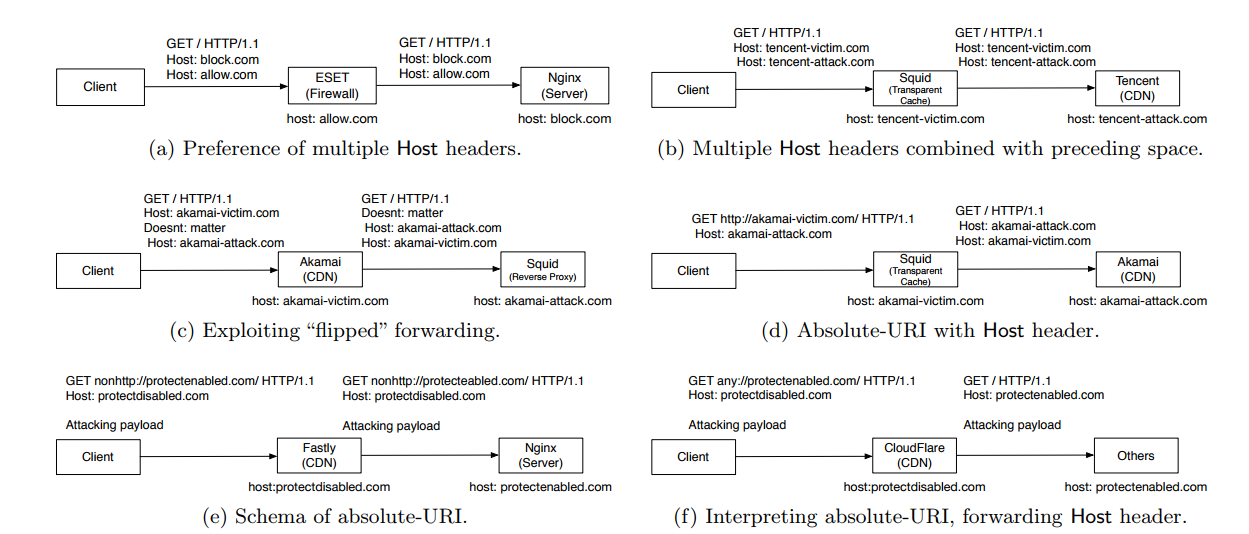
因为 CDN,transparent cache,Server 的实现方法不一样(没有按照 RFC 2616 和 RFC 7320)实现 Host 字段的读取方法。比如说,如果一个 HTTP GET 里面有两个 Host 字段的情况下,有的 CDN 会使用第一个 Host 地址,有的 server 会使用第二个 Host 地址,这样混乱的实现,就暴露了 cache poisoning 和 filtering bypass 两种漏洞。
文章还研究了这个问题影响的范围,受到影响的运营商等等。
Accessorize to a Crime: Real and Stealthy Attacks on State-Of-The-Art Face Recognition
Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer (Carnegie Mellon University) and Michael K. Reiter (University of North Carolina Chapel Hill)

这篇文章非常有意思,简单来说就是能够带一个眼镜,绕过人脸识别系统。下图演示了在佩戴这个眼睛之后就能绕过 DNN 的人脸识别了。

文章的 threat model 是假设攻击者可以通过佩戴一个配件来伪装成另外一个人,也假设了人脸识别系统是一个 white-box,就是内部的结构,参数都是已知的。作者通过阐述现有的基于 DNN 的人脸识别系统,设计了一个优化问题。使用 gradient descent 算法解决 optimization problem 就可以了。后面作者首先使用数字的方法进行试验,也就是在图片上添加一个假的眼睛来测试人脸识别系统,之后使用了真实的打印的眼镜尝试绕过系统。
除了 white-box 的人脸识别系统,文章还讨论了 black-box models,比如说商业的人脸识别系统: Face++。
- related work, cvdazzle: https://cvdazzle.com/
Session 12C Even more attacks
Android ION Hazard: the Curse of Customizable Memory Management System
Hang Zhang, Dongdong She and Zhiyun Qian (University of California, Riverside)

这篇文章介绍了 Android ION 实现问题引起的漏洞。ION 是 unified memory management interface,他是 Linux 的一个 subsystem,主要目的是为 CPU,相机等提供对与内存管理的特殊要求。比如说有些设备需要物理上连续的内存空间,还有一些需要 cache coherency protocol 是 DMA 的功能正常进行。简单来说 ION 为外部设备提供了统一的接口,内部为不同的特殊设备需求,提供了不同种类的 memory heap。
ION 提供的借口就是 /dev/ion 文件,应用可以用 open(), ioctl() 这类的函数操作内存。在 AOSP 中定义了 10 种 heap 的类型,分别提供不同的功能。
了解了 ION 的功能之后,问题出在哪儿了呢?文章主要讨论了两个设计上的问题:
- unified interface: /dev/ion 文件是 world-readable 的(此处只需要 "world-readable" 就能让 ION 分配并管理内存”),并且对于某个应用分配的内存大小也没有限制。所以,这种设计就造成了 DoS 攻击。某个应用分配大量的内存,使得其他的系统服务没办法使用内存,从而出现 deny-of-service 攻击。
- 第二个问题是和 buffer sharing 有关,引发了两个漏洞。
- 有些 ION 的 memory region 是由 hardware security mechanisms 保护的,比如说 TrustZone。那么如果有来自 untrusted-world 的访问,就会引发 exception, 造成系统 crash。
- 第二个漏洞是会造成敏感信息泄露。因为 ION 的 memory page 在 free/allocate 的时候并没有清空。因为以前的实现中假设 memory page 并不能被 user space 访问,但是新的 ION 却能被 user space process 访问。那么,这些可能含有敏感信息的 dirty page 就可以被 user space app 访问到,从而造成信息泄露。
作者在分析这两种设计上的问题,和讨论形成的根本原因之后,提出方法去检测是否存在漏洞。第一个 DoS 的问题比较简单,我着重讲一下 buffer sharing 的检测。
针对 buffer sharing 的漏洞,作者使用了静态污点分析的方法。主要的思路是,首先把 memory allocation 的 size 作为 taint source,而 memset() 函数作为 sink,如果 size 在污点分析的时候被 memset 调用,那么有可能就是被 zero 了。如果没有,就有可能存在 sensitive data leakage 的情况。
作者使用上面的方法分析了市面上主流的几款手机,发现了很多漏洞(见下表):
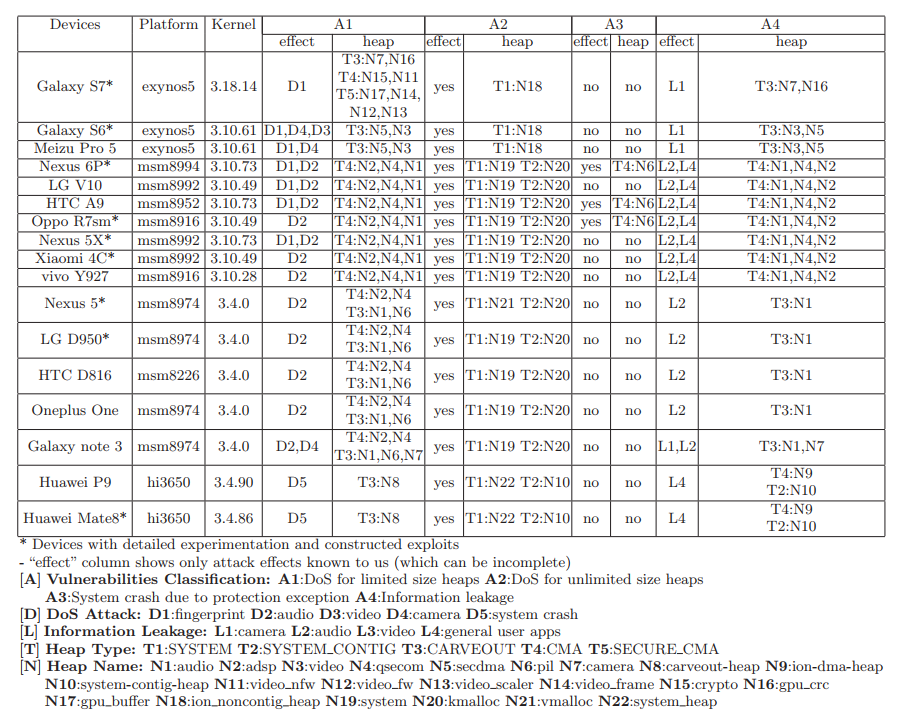
当然,文章中也提到了静态分析方法的准确率,和一些 case study。
总的来说这篇文章对于 Android ION 有很深入的分析,即讲清楚了漏洞的成因,有提供了检测方法,读下来之后学到了很多。
Coverage-based Greybox Fuzzing as Markov Chain
Marcel Boehme, Van-Thuan Pham and Abhik Roychoudhury (National University of Singapore)
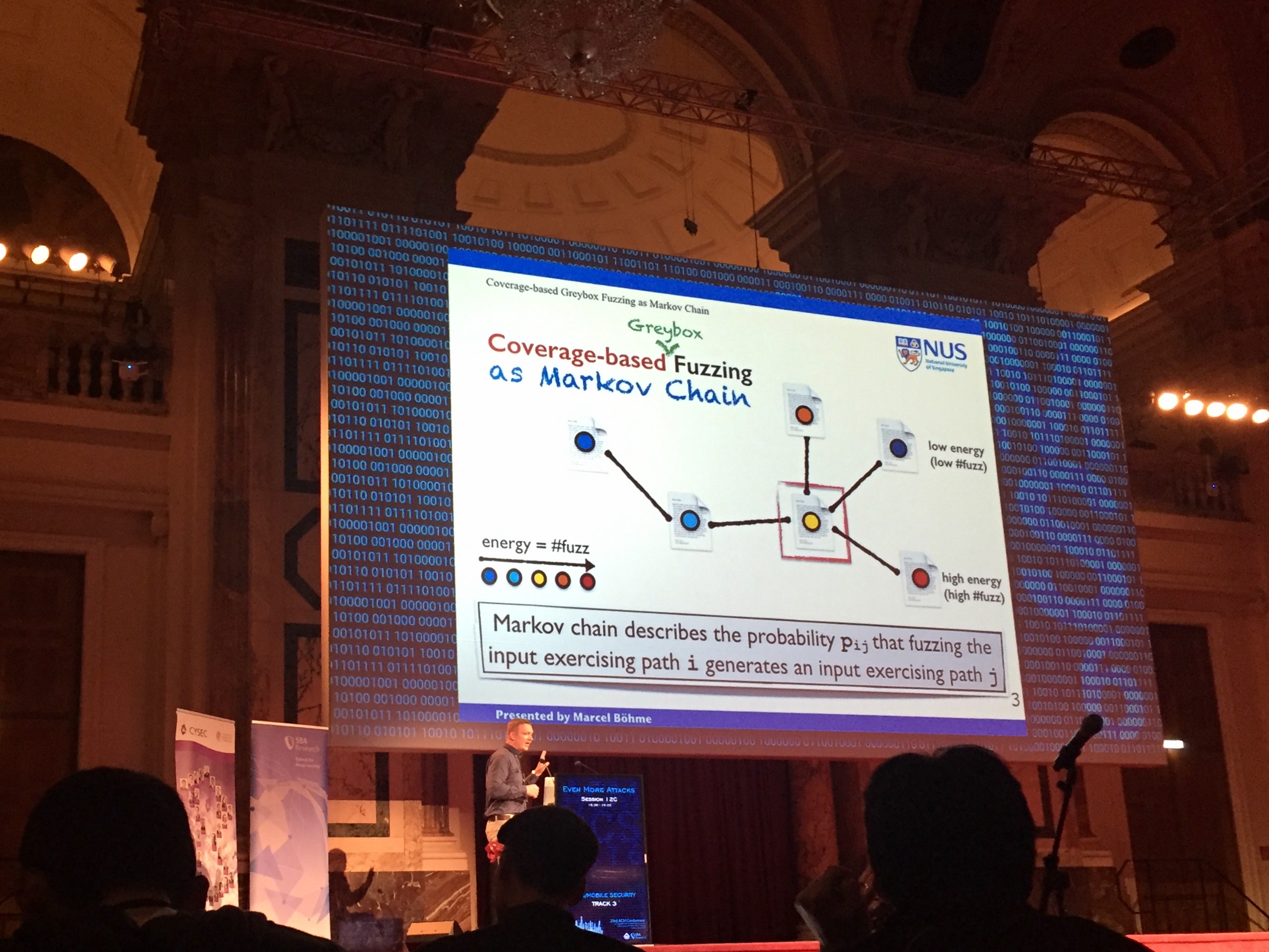
这篇文章改进了 AFL 中使用的 CFG (coverage-based greybox fuzzing),使得策略更加有效。
作者首先把 CFG 作为 Markov chain 进行分析,假设当前种子输入执行的路径是 i,fuzz 之后的路径为 j 的概率为 p_ij。那么称路径从 i 到路径 j 所要生成的测试用例个数为该种子输入的能量(E_ij=1/p_ij)。而AFL计算出的fuzz次数远高于E_ij。
根据分析,作者制定了新的能量分配策略,和种子选择策略。文章使用改进的工具 AFLFast 测试了 binutils, c++filt, nm 和 objdump 等工具,拿到了 9 个 CVE,crash 的数量也非常多。
- 相关文章:http://cgnail.github.io/notes/afl-fast/
Fun
会议上结识了很多小伙伴,会后大家一起在维也纳吃肉玩耍 :)


Conclusion & Thanks
总的来说,这次来维也纳的确不虚此行。CCS 无论从论文质量,还是会议组织,都是首屈一指,明年会议的组织者想必压力很大啊(忘记说了,2018 年的 CCS 将会在 Dallas 举办)。亲临会议听演讲和看论文研究细节确实有很大的区别,每个演讲之后的 Q&A 都会有有价值的提问和讨论。Keynote 和 Panel 都提出了很多新的观点和想法,启迪我未来的科研。引用我导师 John C.S. Lui 在会议上给我讲的一句话:"this is the difference between good conference and prestigious conference"。确实是这样,参加一个 prestigious conference 都深刻的影响这我对于科研理想、信念。在此,对于读了这系列的文章的朋友说一声加油,有可能的话,我们下一届再见。
最后,感谢我的导师 John C.S. Lui 和 Lenx Wei,是他们一直鼓励我在科研道路上前行。感谢 Wan Tao,这个系列的文章的完成,少不了他的编辑/修改。最最后,感谢大家的耐心阅读,我们下次再见!